近年来,中国人工智能公司在将开源生态系统与大语言模型相结合方面积累了丰富经验,取得了显著成果。而美国人工智能企业如今也开始效仿这一模式。特朗普总统的“人工智能行动”计划将开源人工智能模型列为优先发展方向,OpenAI积极响应,推出了gpt - oss模型。这是自GPT - 2以来,OpenAI发布的首套开放权重模型,包含gpt - oss - 20b和gpt - oss - 120b两种配置。

从技术细节来看,gpt - oss - 20b拥有210亿个参数,采用混合专家Transformer架构,具备高达131,072个令牌的上下文窗口,可在16GB显存的平台上运行,这使得大多数现代消费级GPU都能在本地轻松部署该模型。gpt - oss - 120b规模更大,拥有1170亿个参数,推理性能强劲,但运行它至少需要一块英伟达H100平台。
OpenAI此次发布的模型采用Apache 2.0许可证,允许商业使用、修改和重新分发,具有完全开源的性质。这与中国人工智能公司的做法类似,此前中国如深度求索、阿里巴巴等企业已在开源领域深耕多年,而美国除了Meta的LLaMA,主流模型进入开源生态系统的较少。此次OpenAI的举措,无疑是对中国发展模式的一种回应。
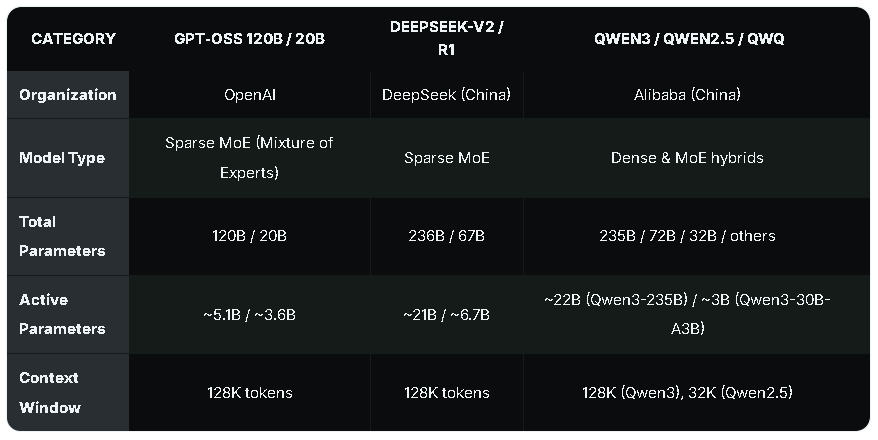
参数对比:中国模型暂居上风
在参数数量方面,中国的人工智能模型表现出色。以深度求索V2、通义千问3等为代表的中国模型,总参数和活跃参数数量均高于OpenAI的gpt - oss模型。例如,深度求索V2的总参数达到2360亿,活跃参数约210亿;通义千问3 - 235B的总参数为2350亿,活跃参数约220亿。而gpt - oss - 120b的总参数为1170亿,活跃参数约51亿;gpt - oss - 20b的总参数为210亿,活跃参数约36亿。
不过,参数数量并非衡量模型性能的唯一标准。虽然目前中国模型在参数方面具有优势,但这主要得益于其多年的技术积累和研发投入。
实际性能:各有千秋
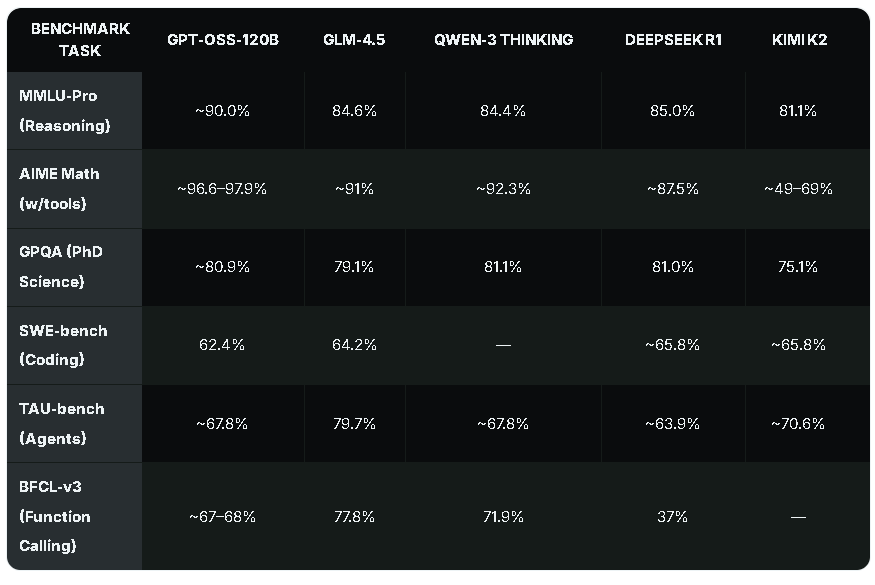
为了更全面地评估这些模型的性能,我们参考了Clarifai的测试数据,对比了它们在多个知名工作负载下的表现,包括大规模多任务语言理解(MMLU)、美国邀请赛数学考试(AIME Math)、博士科学(GPQA)、编码(SWE - 基准测试)、智能体(TAU - 基准测试)和函数调用(BFCL - v3)等。
在推理工作负载和数学运算方面,gpt - oss表现卓越。在MMLU - 专业版测试中,gpt - oss - 120b的准确率约为90.0%,高于其他对比模型;在AIME数学测试中,其准确率更是高达约96.6 - 97.9%,同样领先。此外,gpt - oss的活跃参数占用空间较小,为本地使用提供了更具成本效益的选择。
然而,在智能体工作负载和多语言能力方面,gpt - oss - 120b落后于中国替代产品。在TAU - 基准测试中,gpt - oss - 120b的准确率约为67.8%,而GLM - 4.5达到了79.7%;在多语言相关的测试中,中国模型也展现出了一定的优势。尽管如此,gpt - oss仍然是开源生态系统中的顶级选择。
开放权重模型:行业发展趋势
开放权重模型是人工智能行业的重要发展方向,它为整个生态系统带来了诸多好处。对于开发者而言,开放权重模型提供了更多的学习和研究机会,促进了技术的交流与创新;对于企业来说,可以根据自身需求对模型进行修改和优化,降低开发成本,提高模型的适用性。
OpenAI推出gpt - oss模型,将加强美国在开源人工智能模型领域的地位。此前,该领域一直由中国人工智能公司主导。此次OpenAI的入局,将促使中美两国在人工智能领域展开更激烈的竞争与合作,推动整个行业不断向前发展。山姆·奥特曼及其团队对这一成果想必会感到满意,但未来的竞争仍充满挑战
