在人工智能芯片领域,英伟达长期占据主导地位,但华为正凭借其创新的机架级解决方案向这一格局发起有力挑战。近期,英伟达获准恢复向中国出口H20 GPU,本以为能借此巩固市场,然而华为在上海世界人工智能大会上展示的CloudMatrix 384机架系统,却让局势变得复杂起来。
华为“巨无霸”的强大内核
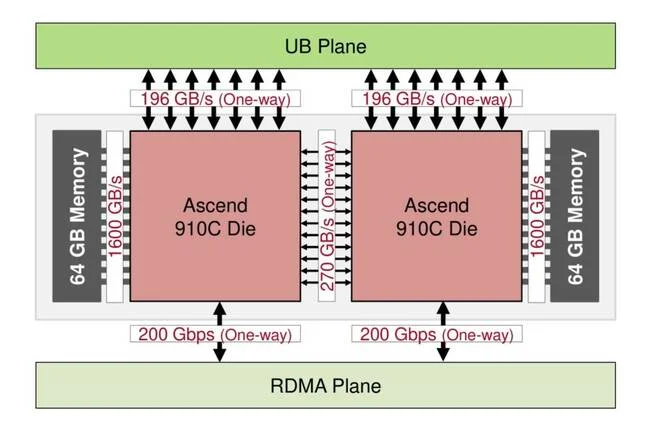
CloudMatrix 384的核心是华为最新一代昇腾NPU——P910C。这款芯片的设计独具匠心,每个加速器由两块计算芯片通过高速芯片间互连技术紧密相连。这种连接方式使得数据传输速率达到双向540GB/s或单向270GB/s,为芯片的高性能运算提供了坚实的保障。

在性能方面,P910C展现出了惊人的实力。其组合可输出752万亿次浮点运算(TFLOPS)的密集FP16/BF16性能,这一数据远超英伟达H20的两倍。同时,它配备的8组高带宽内存,总容量达128GB,为每块计算芯片提供1.6TB/s内存带宽,总带宽高达3.2TB/s,确保了芯片在处理大规模数据时的流畅性。
与英伟达的H200相比,P910C虽然在FP16浮点运算性能上略逊一筹,但考虑到H200无法在中国合法购买,而H20在内存带宽优势不明显的情况下,P910C的HBM容量更大,浮点运算性能更是超过两倍,这使得它成为英伟达中国特供加速器的有力竞争者。而且,华为认为在推理场景下,INT8的性能几乎与FP8同样出色,这进一步提升了P910C的实用性。
集群作战,威力无穷
在人工智能训练和推理领域,单个芯片的性能往往无法满足需求,因此芯片的扩展效率成为了关键。华为深知这一点,在P910C的设计上充分考虑了集群作战的需求。
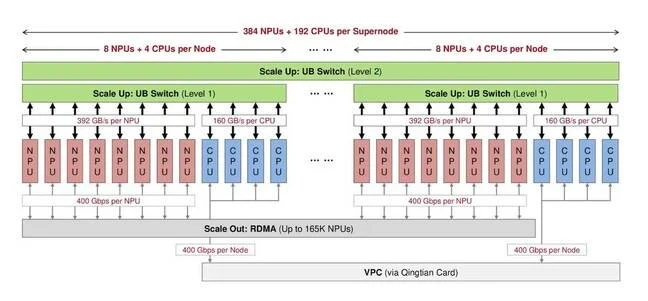
P910C配备的类似NVLink的扩展互连技术或统一总线(UB),为芯片的扩展提供了可能。通过这一技术,华为可以将多个加速器连接成一个超大规模系统,就像英伟达的HGX和NVL72服务器及机架系统一样。每个P910C加速器的14个28GB/s的UB接口,连接到每个节点内置的7个UB交换ASIC,形成了一个完全无阻塞的全互联网络。在这个网络中,每个节点包含8个NPU和4个鲲鹏CPU,为大规模计算提供了强大的支持。
与英伟达的H20或B200不同,华为的UB交换机具有独特的优势。其大量备用端口可连接第二层UB骨干交换机,使得华为能够将每个机架的NPU数量从8个扩展到32个,甚至在一个“超级节点”中扩展到384个。这种扩展能力使得华为的CloudMatrix 384在系统级性能上超越了英伟达的GB200 NVL72。尽管英伟达的GB200 NVL72在机架间性能上表现优异,但其仅支持最多72个GPU的计算域,数量远不及华为。
推理性能,优势尽显
对于人工智能模型来说,推理性能直接影响到实际应用的效果和成本。华为的CloudMatrix 384在推理场景下展现出了显著的优势,尤其是在处理中国近期涌现的大量混合专家(MoE)模型时。
混合专家模型的特点是将复杂任务分解为多个子任务,由不同的专家进行处理。更多芯片意味着可以承载更多的专家,从而更好地利用张量、数据或专家并行等技术,提高推理吞吐量,降低每个token的总体成本。
以DeepSeek R1这样的混合专家模型为例,华为的CloudMatrix-Infer大语言模型推理服务平台可以将其配置为每个NPU芯片承载一个专家。该平台将预填充、解码和缓存解耦,通过UB网络实现缓存数据的高带宽、均匀访问,减少了数据局部性限制,简化了任务调度,提高了缓存效率。
在实际测试中,CloudMatrix-Infer表现出了惊人的性能。单个NPU每秒可处理6688个输入token,同时以每秒1943个token的速度生成输出。虽然在批量大小和单个token输出延迟等方面存在一定限制,但在理想条件下,华为的提示处理效率可达每万亿次浮点运算每秒4.5个token,略高于英伟达H800的3.96个token/秒/万亿次浮点运算。在解码阶段,华为机架系统的表现也略优于英伟达H800,领先约10%。
功耗、密度与成本:挑战与机遇并存
尽管CloudMatrix 384在性能上表现出色,但在功耗、密度和成本方面也面临着一些挑战。从功耗来看,SemiAnalysis推测完整系统的总功耗可能在600千瓦左右,而英伟达GB200 NVL72的功耗约为120千瓦。这意味着英伟达NVL72的计算密度不仅是华为的数倍,功耗效率更是超过3倍。
然而,在中国,廉价电力并非主要瓶颈。近年来,中国政府大力投资国家电网建设,大规模建设太阳能电站和核反应堆,减少了对燃煤电厂的依赖。这为华为CloudMatrix 384的部署提供了一定的便利。
在成本方面,华为CloudMatrix 384的售价约为820万美元,而英伟达NVL72机架系统的单价约为350万美元。对于中国模型开发者来说,由于美国对AI加速器的出口管制,英伟达NVL机架根本不在考虑范围内。华为在机架级市场几乎没有竞争对手,其唯一的瓶颈可能是中芯国际能生产多少P910C芯片。
美国议员认为中芯国际无法大规模生产这种复杂芯片,但回顾过去,行业专家曾认为中芯国际不具备制造7纳米及更小制程芯片的技术,而事实却并非如此。因此,华为CloudMatrix系统的量产规模仍有待观察,但它已经为人工智能芯片市场带来了新的变数。